Многорукий бандит
# Основные идеи
В машинном обучении задача обычно ставится так:
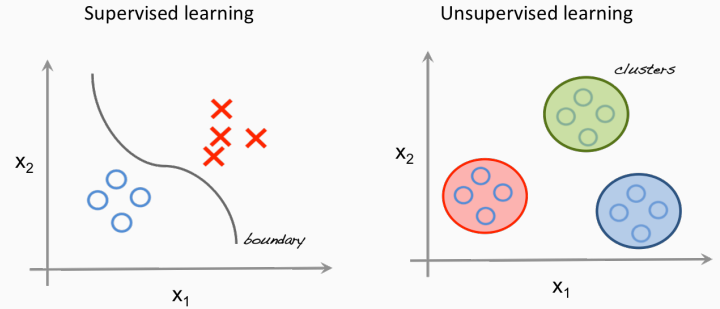
- есть набор «правильных ответов», и нужно его продолжить на всё пространство (supervised learning),
- есть набор тестовых примеров без дополнительной информации, и нужно понять его структуру (unsupervised learning).
Однако во многих случая изначально правильных ответов нет, научиться что-то делать возможно только с помощью собственного опыта. Отсюда и обучение с подкреплением (reinforcement learning). Агент взаимодействует с окружающей средой, предпринимая действия. Окружающая среда его поощряет за эти действия, а агент продолжает их предпринимать.
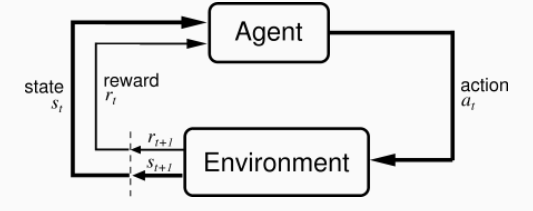
Общая схемы выглядит обучения с подкреплением выглядит так
- На каждом шаге агент может находиться в состоянии s ∈ S.
- На каждом шаге агент выбирает из имеющегося набора действий некоторое действие a ∈ A.
- Окружающая среда сообщает агенту, какую награду r он за это получил и в каком состоянии s′ после этого оказался.
Многорукие бандиты как частный случай обучения с подкреплением
- Формально всё то же самое, но |S| = 1, т.е. состояние агента не меняется. У него фиксированный набор действий A и возможность выбора из этого набора действий.
- Агент как в комнате с игровыми автоматами, пытается дергать ручки, пока на найдет более выиграшную
- Награда как exploration / exploitation tradeoff. То есть выигрыш, минус затраты на эксперименты
Многоруких бандитов можно разделить на два типа — в зависимости от того, какую задачу они призваны решить:
Классические многорукие бандиты (MAB). Это алгоритмы для выбора одного самого эффективного варианта с максимальной потенциальной наградой. Это самый распространённый тип многоруких бандитов, к нему относятся широко известные классические реализации MAB: epsilon-greedy, UCB, Thompson sampling. Алгоритмы MAB не способны улавливать контекстные особенности среды, в которой работают, — они лишь перераспределяют трафик на варианты, где среднестатистически наблюдается наибольшее среднее значение целевой метрики.
Контекстные бандиты (CMAB). Это алгоритмы, направленные на оптимизацию награды в зависимости от контекста среды, в которой они работают. Суть их работы можно описать так: существует некоторая среда, в которой есть определённые закономерности; перед CMAB стоит задача подобрать для субъектов среды такие варианты, которые бы максимизировали награду исходя из этих закономерностей. CMAB по сути это MAB + модели улавливающие состояния (линейные в качестве примера)
# Алгоритмы
Существует несколько алгоритмов применения бандитов.
ε-greedy
Выбираем стратегию с максимальной средней наградой (средним значением метрики, которую мы оптимизируем) и иногда с определённой заранее вероятностью выбираем случайную стратегию для исследования.
UCB (upper confidence bound).
В отличие от ε-greedy, проводит своё исследование не случайно, а на основе растущей со временем неопределённости у стратегий. В начале работы алгоритм случайно задействует все стратегии, после чего рассчитывается средняя награда каждой. Далее выбор стратегии происходит следующим образом:
После каждой итерации обновляются средние награды стратегий. С течением времени чем реже выбиралась та или иная стратегия, тем больше будет у неё неопределённость. Окончательный выбор стратегии — это максимальная сумма средней награды и неопределённости среди всех стратегий.
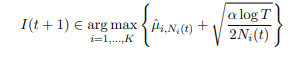
u(t) — среднее значение награды стратегии a, t — общее количество наблюдений, N(t) — количество раз, когда была выбрана стратегия a.
Thompson sampling
Идея: не присваивать какой-то приоритет, а сэмплировать ожидания наград из их апостериорных распределений и выбирать максимальную.
Априорное распределение - распределение, которое выражает предположения до учета экспериментальных данных.
Апостериорное распределение - распределение, которое получено после учёта экспериментальных данных.
Алгоритм
- Задать изначальное Бета-распределение между 0 и 1 для окупаемости каждого варианта.
- Просэмплировать варианты из этого распределения, выбрать максимальный параметр Тета.
- Выбрать такой вариант k, какой бы ассоциировался с самым большим тета.
- Посмотреть, сколько очков набрали, обновить параметры распределения.
# Смысл применения
Основной смысл применения многоруких бандитов в том, чтобы оптимизировать стратегии на основе имеющегося опыта
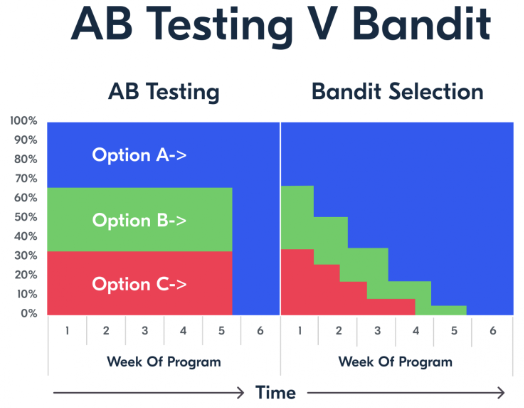
Соответственно с помощью бандитов можно с течением времени выбирать наиболее выгодную стратегию.
Как применять в реальных задачах
- OFFLINE. На основе имеющихся данных о клиентах формируются модели по выбору пула стратегий. Обучаются модели машинного обучения для определения диапозона цен для показал, набора user-item пар и т.д.
- ONLINE. Применяются разные стратегии с использованием бандитов
# Источники
- МНОГОРУКИЕ БАНДИТЫ И RL. Сергей Николенко. СПбГУ − Санкт-Петербург. 24 апреля 2023 г. https://logic.pdmi.ras.ru/~sergey/teaching/mlspsu22/26-bandits.pdf
- Контекст, награда, много рук. Многорукие бандиты как метод принятия решений https://habr.com/ru/companies/ozontech/articles/738318/