сверточные сети
# Определение
Свертки (2D convolutions) - представляют собой основной строительный блок сверточных нейронных сетей и нашли широкое применение в обработке различных видов данных, включая аудио, текст и даже временные ряды. Однако их популярность достигла пика при применении к задачам классификации изображений.
Изображения можно рассматривать как матрицы пикселей. Для представления черно-белых изображений используется один канал (Grayscale), в то время как для цветных изображений применяются три канала (RGB - красный, зеленый, синий).
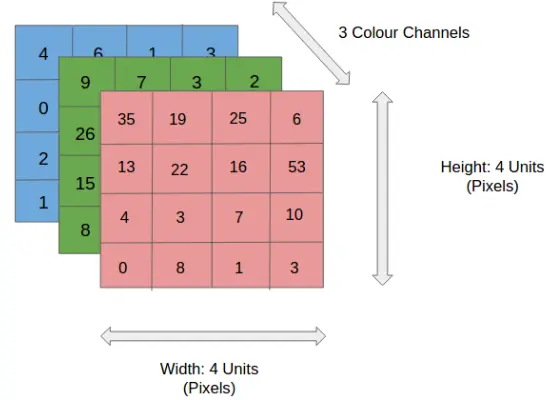
Как обрабатывали изображения до появления сверток? Это было довольно просто - все пиксели изображения последовательно собирали в один массив. Можете представить, насколько большим может быть такой массив для hq изображения. Это первое ограничение такого подхода. Второе ограничение заключается в том, что при переходе к такому представлению мы теряем информацию о пространственном расположении объектов на изображении.
Чтобы объяснить свертки, давайте проведем аналогию с применением фильтра к изображению. Допустим, у нас есть фильтр размером 3x3, и мы хотим применить его к черно-белому изображению с одним каналом.
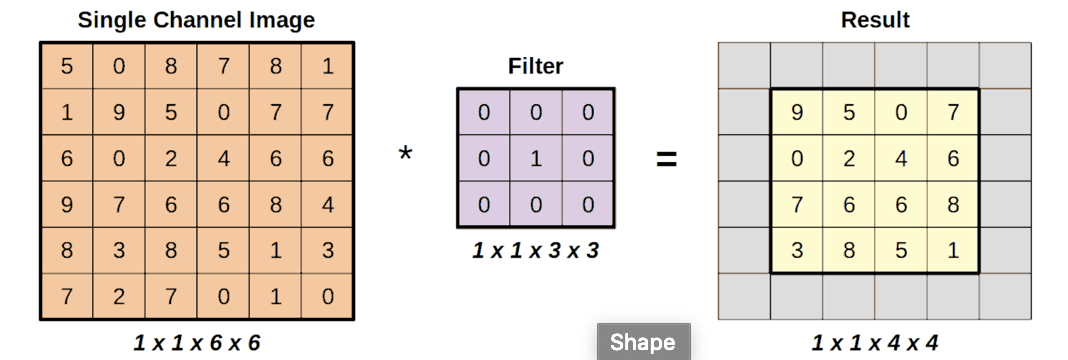
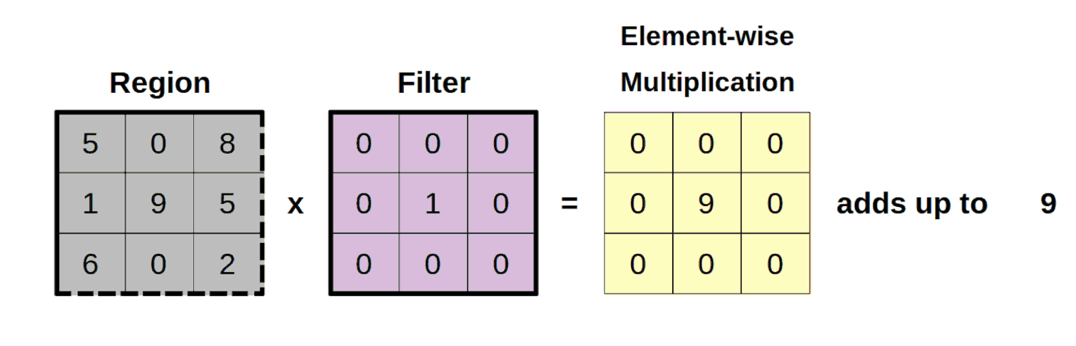
Свертки (2D convolutions) выполняют поэлементное умножение между двумя массивами, region и filter, а затем суммируют все полученные значения. Эта операция по сути является скалярным произведением (dot product).
Свертки позволяют нам применить фильтр к изображению и получить интересующие нас данные, сохраняя при этом пространственную информацию.
Для регулирования размера выходного изображения и выбора данных, которые будут взяты в окне свертки, используют параметры padding и striding.
- Padding расширяет входную матрицу путем добавления нужного количества дополнительных строк и столбцов, чаще всего заполняемых нулями.
- Striding позволяет задать шаг, с которым будет применяться свертка к изображению. Этот параметр влияет на размер выходного изображения.
После применения свертки к изображению, обычно используют активационную функцию, такую как ReLU, для выделения “feature maps” и далее применяют операцию пулинга (pooling) для уменьшения размера “feature map”, при этом сохраняя важные данные.
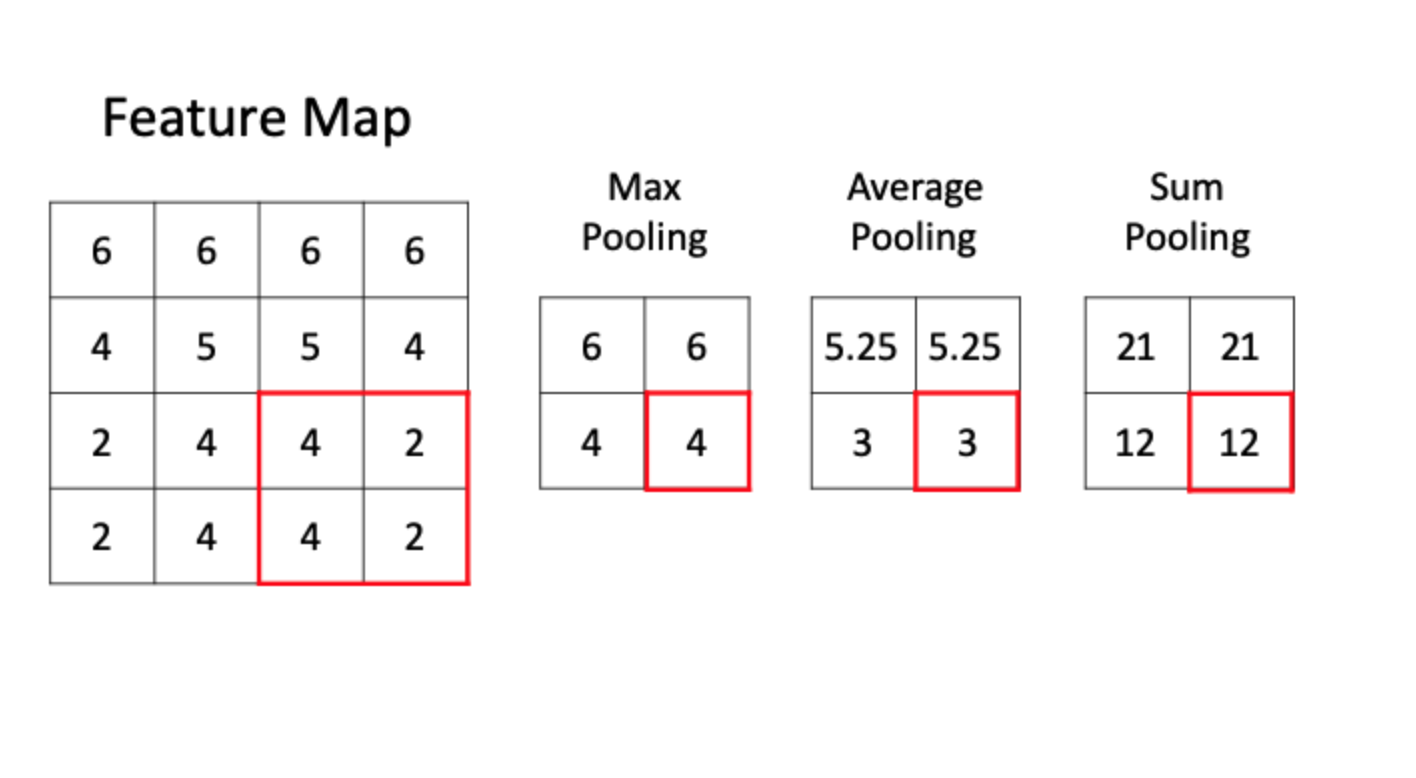
Max Pooling: в этой операции выбирается максимальное значение из окна, и оно сохраняется. Максимальное пулинг часто используется для выделения наиболее активных функций в данном окне
Average Pooling: здесь вычисляется среднее значение всех элементов в окне, может помочь сгладить данные и уменьшить размерность, сохраняя при этом основную информацию.
Sum Pooling: суммируются все значения в окне. Это может быть полезно, если важна суммарная информация.
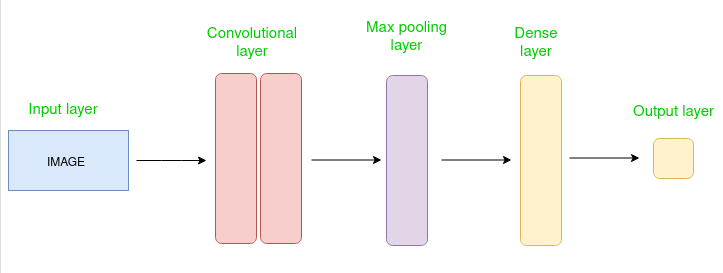
В данном примере представлена простейшая архитектура сверточной нейронной сети (CNN). Современные нейронные сети имеют гораздо более сложные архитектуры с множеством слоев и разнообразными подходами. Например, архитектуры, объединяющие принципы трансформера и сверточных сетей, такие как Conformer, получили широкое распространение.
Классические модели CNN, такие как ResNet, EfficientNet, MobileNet и другие, используются в качестве “основы” (backbone) в более сложных архитектурах. Они внесли значительный вклад в развитие нейронных сетей и остаются важными инструментами и по сей день.

Давайте рассмотрим известный набор данных MNIST, который является игрушечным датасетом, содержащим изображения рукописных цифр от 0 до 9. Каждое изображение в этом датасете имеет размер 28 × 28 пикселей. Для решения задачи с использованием фреймворка PyTorch, нам необходимо создать простейшую нейронную сеть, нам нужно определить все необходимые слои: сверточные (convolutional), активации (activation), пуллинг (pooling) и полносвязанные (fully connected) слои. Также мы должны написать код для предварительной обработки данных и цикл обучения нейронной сети.
# Пример использования
| |
# Связи
# Ссылки
https://stanford.edu/~shervine/teaching/cs-230/cheatsheet-convolutional-neural-networks https://github.com/sooftware/conformer